R in Insurance Conference, London, 15 July 2013

The first conference on R in Insurance will be held on Monday 15 July 2013 at Cass Business School in London, UK.
The intended audience of the conference includes both academics and practitioners who are active or interested in the applications of R in insurance.
This one-day conference will focus on applications in insurance and actuarial science that use R, the lingua franca for statistical computation. Topics covered may include actuarial statistics, capital modelling, pricing, reserving, reinsurance and extreme events, portfolio allocation, advanced risk tools, high-performance computing, econometrics and more. All topics will be discussed within the context of using R as a primary tool for insurance risk management, analysis and modelling.
The intended audience of the conference includes both academics and practitioners who are active or interested in the applications of R in insurance.
The 2013 R in Insurance conference builds upon the success of the R in Finance and R/Rmetrics events. We expect invited keynote lectures by:
- Professor Alexander McNeil, Department of Actuarial Science & Statistics
Heriot-Watt University - Trevor Maynard, Head of Exposure Management and Reinsurance, Lloyd's
Details about the registration and abstract submission are given on the R in Insurance event web site of Cass Business School.
You can contact us via rinsuranceconference at gmail dot com.
The organisers, Andreas Tsanakas and Markus Gesmann, gratefully acknowledge the sponsorship of Mango Solutions.
Now I see it! K-means cluster analysis in R
I can't resist to write about this here as well. David's first post is about k-means cluster analysis. One of the popular algorithms for k-means is Lloyd's algorithm. So, on that note I will use a picture of the Lloyd's of London building to play around with David's code, despite the fact that the two Lloyd have nothing to do with each other. Lloyd's provides pictures of its building copyright free on its web site. However, I will use a reduced file size version, which I copied to GitHub.
The jpeg package by Simon Urbanek [3] allows me to load a jpeg-file into R. The R object of the images is an array, which has the structure of three layered matrices, representing the value of the colours red, green and blue for each x and y coordinate. I convert the array into a data frame, as this is an accepted structure by k-means and plot the data.
library(jpeg)
library(RCurl)
url <-"https://raw.githubusercontent.com/mages/diesunddas/master/Blog/LloydsBuilding.jpg"
readImage <- readJPEG(getURLContent(url, binary=TRUE))
dm <- dim(readImage)
rgbImage <- data.frame(
x=rep(1:dm[2], each=dm[1]),
y=rep(dm[1]:1, dm[2]),
r.value=as.vector(readImage[,,1]),
g.value=as.vector(readImage[,,2]),
b.value=as.vector(readImage[,,3]))
plot(y ~ x, data=rgbImage, main="Lloyd's building",
col = rgb(rgbImage[c("r.value", "g.value", "b.value")]),
asp = 1, pch = ".")
Running a k-means analysis on the three colour columns in my data frame allows me to reduce the picture to k colours. The output gives me for each x and y coordinate the colour cluster it belongs to. Thus, I plot my picture again, but replace the original colours with the cluster colours.
Comparing regions: maps, cartograms and tree maps

library(RColorBrewer)
library(rworldmap)
data(countryExData)
par(mai=c(0,0,0.2,0),xaxs="i",yaxs="i")
mapByRegion( countryExData,
nameDataColumn="GDP_capita.MRYA",
joinCode="ISO3", nameJoinColumn="ISO3V10",
regionType="Stern", mapTitle=" ", addLegend=FALSE,
FUN="mean", colourPalette=brewer.pal(6, "Blues"))Greenland appears to be of the same size as Brazil or Australia and Africa seems to be only about four times as big as Greenland. Of course this is not true. Africa is about 14 times the size of Greenland, while Brazil and Australia are about four times the size of Greenland, with Brazil slightly larger than Australia and nine times the population. Thus, talking about regional opportunities without a comparable scale can give a misleading picture.
Of course you can use a different projection and XKCD helps you to find one which fits your personality. On the other hand, Michael Gastner and Mark Newman developed cartograms, which can reshape the world based on data [1]. Doing this in R is a bit tricky. Duncan Temple Lang provides the Rcartogram package on Omegahat based on Mark Newman's code and Mark Ward has some examples using the package on his 2009 fall course page to get you started.
A simple example of a cartogram is given as part of the maps package. It shows the US population by state:
Changing colours and legends in lattice plots
Eventually I would like to get the following result:

I start with a simple bar chart, using the
Insurance data set of the MASS package.Please note that if you use R-2.15.2 or higher you may get a warning message with the current version of lattice (0.20-10), but this is a known issue, and I don't think you need to worry about it.
library(MASS)
library(lattice)
## Plot the claims frequency against age group by engine size and district
barchart(Claims/Holders ~ Age | Group, groups=District,
data=Insurance, origin=0, auto.key=TRUE)
To change the legend I specify a list with the various options for
auto.key. Here I want to set the legend items next to each other, add a title for the legend and change its font size:
Data.table rocks! Data manipulation the fast way in R
data.table. The speed and simplicity of this R package are astonishing. Here is a simple example: I have a data frame showing incremental claims development by line of business and origin year. Now I would like add a column with the cumulative claims position for each line of business and each origin year along the development years.
It's one line with
data.table! Here it is:myData[order(dev), cvalue:=cumsum(value), by=list(origin, lob)]':=' works by reference and is one of the reasons why data.table is so fast.
And it is getting even better. Suppose you want to get the latest claims development position for each line of business and origin year. Again, it is only one line:
Claims reserving in R: ChainLadder 0.1.5-4 released
ChainLadder package on CRAN. The R package provides methods which are typically used in insurance claims reserving. If you are new to R or insurance check out my recent talk on Using R in Insurance.The chain-ladder method which is a popular method in the insurance industry to forecast future claims payments gave the package its name. However, the
ChainLadder package has many other reserving methods and models implemented as well, such as the bootstrap model demonstrated below. It is a great starting point to learn more about stochastic reserving.Since we published version 0.1.5-2 in March 2012 additional functionality has been added to the package, see the change log, but in particular the vignette has come a long way.
Many thanks to my co-authors Dan Murphy and Wayne Zhang.
Simulating neurons or how to solve delay differential equations in R
My model is based on the paper: Epileptiform activity in a neocortical network: a mathematical model by F. Giannakopoulos, U. Bihler, C. Hauptmann and H. J. Luhmann. The article presents a flexible and efficient modelling framework for:
- large populations with arbitrary geometry
- different synaptic connections with individual dynamic characteristics
- cell specific axonal dynamics
Time for an old classic game: Moon-buggy
googleVis 0.3.3 is released and on its way to CRAN
So, what changed since version 0.3.2?
Not much, but
plot.gvis didn't open a browser window when options(gvis.plot.tag) were not set to NULL, but the user explicitly called plot.gvis with tag NULL. Thanks to Sebastian Kranz for reporting this bug. Additionally the vignette has been updated and includes an extended section on knitr. As usual, you can download the most recent version from our project site. It will take a few days before version 0.3.3 will be available on CRAN for all operating systems.
googleVis 0.3.2 is released: Better integration with knitr

So what's new in googleVis 0.3.2?
The default behaviour of the functionsprint.gvis and plot.gvis can be set via options(). Now this doesn't sound too exciting but it can be tremendously helpful when you write Markdown files for
knitr. Here is why:googleVis 0.3.0/0.3.1 is released: It's faster!
gvisMotionChart function in the World Bank demo is over 35 times faster. Thanks to ideas by Wei Luo and in particular to Sebastian Kranz for providing the code.plot.gvis has gained a new argument 'browser'. This argument is passed on to the function browseURL. The 'browser' argument is by default set to the output of getOption("browser") in an interactive session, otherwise to 'false'. This prevents R CMD CHECK trying to open browser windows during the package checking process.plot.gvis handles the check if R is running interactively internally. The bug has been fixed in googleVis-0.3.1, not yet available on CRAN, but on our project download page. Thanks to Henrik Bengtsson and Sebastian Kranz for their comments, suggestions and quick response.From guts to data driven decision making
 |
| Source: Wikipedia, License: CC0 |
The whole sketch is hilarious and is often regarded as a fine observation of miss-communication.
Yet, I think it really points out two different approaches in decision making: You can trust your guts or use data/measurements to support your decision.
Review: Kölner R Meeting 5 October 2012
The evening was sponsored by Revolution Analytics, who provided funding which went towards the Kölner R user group Meetup page. We had a good turn-out with 18 participants showing up and three talks by Dominik Liebl, Jonas Stein and Sarah Westrop.
 |  |  |
| Photos: Günter Faes |
Connecting the real world to R with an Arduino
It can be done as Matt Shottwell showed with his home made ECG and a patched version of R at useR! 2011. However, there are other options as well and here I will use an Arduino. The Arduino is an open-source electronics prototyping platform. It has been around for a number of years and is very popular with hardware hackers. So, I had to have a go at the Arduino as well.
 |
| My Arduino starter kit from oomlout |
The example I will present here is silly - it doesn't do anything meaningful and yet I believe it shows the core building blocks for future projects: Read an analog signal into the computer via the Arduino, transform it with R through Rserve and display it graphically in real time. The video below demonstrates the final result. As I turn the potentiometer random points are displayed on the screen, with the standard deviation set by the analog output (A0) of the Arduino and fed into the
rnorm function in R, while at the same time the LED brightness changes.Next Kölner R User Meeting: 5 October 2012
The next Cologne R user group meeting is scheduled for 5 October 2012. All details and the agenda are available on the KölnRUG Meetup site. Please sign up if you would like to come along. Notes from the last Cologne R user group meeting are available here.
Thanks also to Revolution Analytics, who are sponsoring the Cologne R user group as part of their vector programme.

Using R in Insurance, Presentation at GIRO 2012
This year's conference is in Brussels from 18 - 21 September 2012. Despite the fact that Brussels is actually in Belgium the UK actuaries will travel all the way to enjoy good beer and great talks.
On Wednesday morning I will run a session on Using R in insurance. It would be great to see some of you there.

I prepared the slides with R, RStudio, knitr, pandoc and slidy again. My title page shows a word cloud about the GIRO conference. It uses the wordcloud package and was inspired by Ian Fellows' post on FellStats.
The last slide shows the output of sessionInfo(). I am sure it will become helpful one day, when I have to remind myself how I actually created the slides and which packages and versions I used.
Connecting data to the real world - The next sexy job?
At last week's Royal Statistical Society (RSS) conference Hal Varian, Chief Economist at Google, gave a panel talk about 'Statistics at Google'. Could he get a better audience than the RSS?
Hal talked about his career in academia and at Google. He reminded us of the days when Google was still a small start up with no real idea about how they could actually generate revenue. At that time Eric Schmidt asked him to 'take a look' at advertising because 'it might make us a little money'. Thus, Hal got involved in Google's ad auctions.
 |
| Hal Varian at the Royal Statistical Society conference 2012 |
Another projects Hal talked about was predicting the present. Predicting the present, or 'nowcasting', is about finding correlations between events. The idea is to forecast economic behaviour, which in return can help to answer when to run certain ads. He gave the example of comparing the search requests for 'vodka' (peaking Saturdays) with 'hangover' (peaking Sundays) using Google Insight.
Interactive web graphs with R - Overview and googleVis tutorial
Today I feel very lucky, as I have been invited to the Royal Statistical Society conference to give a tutorial on interactive web graphs with R and googleVis.

I prepared my slides with RStudio, knitr, pandoc and slidy, similar to my Cambridge R talk. You can access the RSS slides online here and you find the original R-Markdown file on github. You will notice some HTML code in the file, which I had to use to overcome my knowledge gaps of Markdown or its limitations. However, my output format will always be HTML, so that should be ok. To convert the Rmd-file into a HTML slidy presentation execute the following statements on the command line:
Rscript -e "library(knitr); knit('googleVis_at_RSS_2012.Rmd')"
pandoc -s -S -i -t slidy --mathjax googleVis_at_RSS_2012.md
-o googleVis_at_RSS_2012.html
Are career motivations changing?
The German news magazine Der Spiegel published a series of articles [1, 2] around career developments. The stories suggest that career aspirations of young professionals today are somewhat different to those of previous generations in Germany.
Apparently money and people management responsibility are less desirable for new starters compared to being able to participate in interesting projects and to maintain a healthy work life balance. Hierarchies are seen as a mean to an end, and should be more flexible, depending on requirements and skills sets. Similar to how they evolve in online communities and projects.
Sigma motion visual illusion in R
Michael Bach, who is a professor and vision scientist at the University of Freiburg, maintains a fascinating site about visual illusions. One visual illusion really surprised me: the sigma motion.
The sigma motion displays a flickering figure of black and white columns. Actually it is just a chart, as displayed below, with the columns changing backwards and forwards from black to white at a rate of about 30 transitions per second.

googleVis 0.2.17 is released: Displaying earth quake data
The next version of the googleVis package has been released on the project site and CRAN.
This version provides updates to the package vignette and a new example for the gvisMerge function. The new sections of the vignette have been featured on this blog in more detail earlier:
- Using
googleViswithknitr(Link to post)
- Using
RookwithgoogleVis(Link to post)
- Using
ReducewithgvisMergeto display several charts on a page (Link to post)
London Olympics 100m men's sprint results

My simple log-linear model predicted a winning time of 9.68s with a prediction interval from 9.39s to 9.97s. Well, that is of course a big interval of more than half a second, or ±3%. Yet, the winning time was only 0.05s away from my prediction. That is less than 1% difference. Not bad for such a simple model.
Rook rocks! Example with googleVis
What is Rook?
Rook is a web server interface for R, written by Jeffrey Horner, the author of rApache and brew. But unlike other web frameworks for R, such as brew, R.rsp (which I have used in the past1), Rserve, gWidgetWWWW or sumo (which I haven't used yet) Rook appears incredible lightweight.
Rook doesn't need any configuration. It is an R package, which works out of the box with the R HTTP server (R ≥ 2.13.0 required). That means no configuration files are needed. No files have to be placed in particular folders, and I don't have to worry about access permissions. Instead, I can run web applications on my local desktop.
 |
| Screen shot of a Rook app running in a browser |
Web applications have the big advantage that they run in a browser and hence are somewhat independent of the operating systems and installed software. All I need is R and a web browser. But here is the catch: I have to learn a little bit about the HTTP protocol to develop Rook apps.
London Olympics and a prediction for the 100m final
It is less than a week before the 2012 Olympic games will start in London. No surprise therefore that the papers are all over it, including a lot of data and statistis around the games.
The Economist investigated the potential financial impact on sponsors (some benefits), tax payers (no benefits) and the athletes (if they are lucky) in its recent issue and video.
The Guardian has a whole series around the Olympics, including the data of all Summer Olympic Medallists since 1896.
100m men final
The biggest event of the Olympics will be one of the shortest: the 100 metres men final. It will be all over in less than 10 seconds. In 1968 Jim Hines was the first gold medal winner, who achieved a sub-ten-seconds time and since 1984 all gold medal winners have run faster than 10 seconds. The historical run times of the past Olympics going back to 1896 are available from databasesport.com.
Looking at the data it appears that a simple log-linear model will give a reasonable forecast for the 2012 Olympic's result (ignoring the 1896 time). Of course such a model doesn't make sense forever, as it would suggest that future run-times will continue to shrink. Hence, some kind of logistics model might be a better approach, but I have no idea what would be a sensible floor for it. Others have used ideas from extreme value theory to investigate the 100m sprint, see the paper by Einmahl and Smeets, which would suggest a floor greater than 9 seconds.
 |
| Historical winning times for the 100m mean final. Red line: log-linear regression, black line: logistic regression. |
My simple log-linear model forecasts a winning time of 9.68 seconds, which is 1/100 of a second faster than Usain Bolt's winning time in Beijing in 2008, but still 1/10 of a second slower than his 2009 World Record (9.58s) in Berlin.
Never-mind, I shall stick to my forecast. The 100m final will be held on 5 August 2012. Now even I get excited about the Olympics, and be it for less than 10 seconds.
R code
Here is the R code used in this the post:
library(XML)
library(drc)
url <- "http://www.databaseolympics.com/sport/sportevent.htm?enum=110&sp=ATH"
data <- readHTMLTable(readLines(url), which=2, header=TRUE)
golddata <- subset(data, Medal %in% "GOLD")
golddata$Year <- as.numeric(as.character(golddata$Year))
golddata$Result <- as.numeric(as.character(golddata$Result))
tail(golddata,10)
logistic <- drm(Result~Year, data=subset(golddata, Year>=1900), fct = L.4())
log.linear <- lm(log(Result)~Year, data=subset(golddata, Year>=1900))
years <- seq(1896,2012, 4)
predictions <- exp(predict(log.linear, newdata=data.frame(Year=years)))
plot(logistic, xlim=c(1896,2012),
ylim=c(9.5,12),
xlab="Year", main="Olympic 100 metre",
ylab="Winning time for the 100m men's final (s)")
points(golddata$Year, golddata$Result)
lines(years, predictions, col="red")
points(2012, predictions[length(years)], pch=19, col="red")
text(2012, 9.55, round(predictions[length(years)],2))
Update 5 August 2012
You find a comparison of my forecast to the final outcome of Usain Bolt's winning time of 9.63s on my follow-up post.Bridget Riley exhibition in London
The other day I saw a fantastic exhibition of work by Bridget Riley. Karsten Schubert, who is Riley's main agent, has a some of her most famous and influential artwork from 1960 - 1966 on display, including the seminal Moving Squares from 1961.
 |
| Photo of Moving Squares by Bridget Riley, 1961 Emulsion on board, 123.2 x 121.3cm |
In the 1960s Bridget Riley created some great black and white artwork, which at a first glance may look simple and deterministic or sometimes random, but has fascinated me since I saw some of her work for the first time about 9 years ago at the Tate Modern.
Her work prompted a very simple question to me: When does a pattern appear random? As human beings most of our life is focused on pattern recognition. It is about making sense of the world around us, being able to understand what people are saying; seeing lots of different things and yet knowing when something is a table and when it is not. No surprise, I suppose, that pattern recognition is such a big topic in statistics and machine learning.
Of course I couldn't resist trying to reproduce the Moving Squares in R. Here it is:
## Inspired by Birdget Riley's Moving Squares
x <- c(0, 70, 140, 208, 268, 324, 370, 404, 430, 450, 468,
482, 496, 506,516, 523, 528, 533, 536, 542, 549, 558,
568, 581, 595, 613, 633, 659, 688, 722, 764, 810)
y <- seq(from=0, to=840, by=70)
m <- length(y)
n <- length(x)
z <- t(matrix(rep(c(0,1), m*n/2), nrow=m))
image(x[-n], y[-m], z[-n,-m], col=c("black", "white"),
axes=FALSE, xlab="", ylab="")
However, what may look similar on screen is quite different when you see the actual painting. Thus, if you are in London and have time, make your way to the gallery in Soho. I recommend it!
Review: Kölner R Meeting 6 July 2012
The second Cologne R user meeting took place last Friday, 6 July 2012, at the Institute of Sociology. Thanks to Bernd Weiß, who provided the meeting room, we didn't have to worry about the infrastructure, like we did at our first gathering.
Again, we had an interesting mix of people turning up, with a very diverse background from chemistry to geo-science, energy, finance, sociology, pharma, physics, psychology, mathematics, statistics, computer science, telco, etc. Yet, the gender mix was still somewhat biased, with only one female attendee.
We had two fantastic talks by Bernd Weiß and Stephan Sprenger. Bernd talked about Emacs' Org-Mode and R. He highlighted the differences between literate programming and reproducible research and if you follow his slides, you get the impression that Emacs with Org-mode is the all-singing-all-dancing editor, or for those who speak German: eine eierlegende Wollmilchsau.

Applying a function successively in R

At the R in Finance conference Paul Teetor gave a fantastic talk about Fast(er) R Code. Paul mentioned the common higher-order function Reduce, which I hadn't used before.
Reduce allows me to apply a function successively over a vector.
What does that mean? Well, if I would like to add up the figures 1 to 5, I could say: add <- function(x,y) x+y
add(add(add(add(1,2),3),4),5)
Reduce(add, 1:5)
Reminder: Next Kölner R User Meeting 6 July 2012
This post is a quick reminder that the next Cologne R user group meeting is only one week away. We will meet on 6 July 2012. The meeting will kick off at 18:00 with three short talks at the Institute of Sociology and will continue, even more informal, from 20:00 in a pub (LUX) nearby.
All details are available on the KölnRUG Meetup site. Please sign up if you would like to come along. Notes from the first Cologne R user group meeting are available here.

Hodgkin-Huxley model in R
One of the great research papers of the 20th century celebrates its 60th anniversary in a few weeks time: A quantitative description of membrane current and its application to conduction and excitation in nerve by Alan Hodgkin and Andrew Huxley. Only shortly after Andrew Huxley died, 30th May 2012, aged 94.
In 1952 Hodgkin and Huxley published a series of papers, describing the basic processes underlying the nervous mechanisms of control and the communication between nerve cells, for which they received the Nobel prize in physiology and medicine, together with John Eccles in 1963.
Their research was based on electrophysiological experiments carried out in the late 1940s and early 1950 on a giant squid axon to understand how action potentials in neurons are initiated and propagated.
Dynamical systems in R with simecol
This evening I will talk about Dynamical systems in R with simecol at the LondonR meeting.
Thanks to the work by Thomas Petzoldt, Karsten Rinke, Karline Soetaert and R. Woodrow Setzer it is really straight forward to model and analyse dynamical systems in R with their deSolve and simecol packages.
I will give a brief overview of the functionality using a predator-prey model as an example.
This is of course a repeat of my presentation given at the Köln R user group meeting in March.
For a further example of a dynamical system with simecol see my post about the Hodgkin-Huxley model, which describes the action potential of a giant squid axon.
I shouldn't forget to mention the other talks tonight as well:
- Writing R for Dummies - Andrie De Vries
- News from data.table 1.6, 1.7 and 1.8 - Matthew Dowle
- Converting S Plus Applications into R - Andy Nicholls (postponed to 18 September 2012)
Transforming subsets of data in R with by, ddply and data.table
As an example I use a data set which shows sales figures by product for a number of years:
df <- data.frame(Product=gl(3,10,labels=c("A","B", "C")),
Year=factor(rep(2002:2011,3)),
Sales=1:30)
head(df)
## Product Year Sales
## 1 A 2002 1
## 2 A 2003 2
## 3 A 2004 3
## 4 A 2005 4
## 5 A 2006 5
## 6 A 2007 6

- base R with
by, ddplyof theplyrpackage,data.tableof the package with the same name.
by
The idea here is to useby to split the data for each year and to apply the transform function to each subset to calculate the share of sales for each product with the following function: fn <- function(x) x/sum(x). Having defined the function fn I can apply it in a by statement, and as its output will be a list, I wrap it into a do.call command to row-bind (rbind) the list elements:R1 <- do.call("rbind", as.list(
by(df, df["Year"], transform, Share=fn(Sales))
))
head(R1)
## Product Year Sales Share
## 2002.1 A 2002 1 0.03030303
## 2002.11 B 2002 11 0.33333333
## 2002.21 C 2002 21 0.63636364
## 2003.2 A 2003 2 0.05555556
## 2003.12 B 2003 12 0.33333333
## 2003.22 C 2003 22 0.61111111
ddply
Hadely's plyr package provides an elegant wrapper for this job with theddply function. Again I use the transform function with my self defined fn function:library(plyr)
R2 <- ddply(df, "Year", transform, Share=fn(Sales))
head(R2)
## Product Year Sales Share
## 1 A 2002 1 0.03030303
## 2 B 2002 11 0.33333333
## 3 C 2002 21 0.63636364
## 4 A 2003 2 0.05555556
## 5 B 2003 12 0.33333333
## 6 C 2003 22 0.61111111
data.table
With data.table I have to do a little bit more legwork, in particular I have to think about the indices I need to use. Yet, it is still straight forward:library(data.table)
## Convert df into a data.table
dt <- data.table(df)
## Set Year as a key
setkey(dt, "Year")
## Calculate the sum of sales per year(=key(dt))
X <- dt[, list(SUM=sum(Sales)), by=key(dt)]
## Join X and dt, both have the same key and
## add the share of sales as an additional column
R3 <- dt[X, list(Sales, Product, Share=Sales/SUM)]
head(R3)
## Year Sales Product Share
## [1,] 2002 1 A 0.03030303
## [2,] 2002 11 B 0.33333333
## [3,] 2002 21 C 0.63636364
## [4,] 2003 2 A 0.05555556
## [5,] 2003 12 B 0.33333333
## [6,] 2003 22 C 0.61111111
data.table may look cumbersome compared to ddply and by, I will show below that it is actually a lot faster than the two other approaches.Plotting the results
With any of the three outputs I can create the chart from above withlatticeExtra:library(latticeExtra)
asTheEconomist(
xyplot(Sales + Share ~ Year, groups=Product,
data=R3, t="b",
scales=list(relation="free",x=list(rot=45)),
auto.key=list(space="top", column=3),
main="Product information")
)
Comparing performance of by, ddply and data.table
Let me move on to a more real life example with 100 companies, each with 20 products and a 10 year history:set.seed(1)
df <- data.frame(Company=rep(paste("Company", 1:100),200),
Product=gl(20,100,labels=LETTERS[1:20]),
Year=sort(rep(2002:2011,2000)),
Sales=rnorm(20000, 100,10))
r1 <- system.time(
R1 <- do.call("rbind", as.list(
by(df, df[c("Year", "Company")],
transform, Share=fn(Sales))
))
)
r2 <- system.time(
R2 <- ddply(df, c("Company", "Year"),
transform, Share=fn(Sales))
)
r3 <- system.time({
dt <- data.table(df)
setkey(dt, "Year", "Company")
X <- dt[, list(SUM=sum(Sales)), by=key(dt)]
R3 <- dt[X, list(Company, Sales, Product, Share=Sales/SUM)]
})r1 # by
## user system elapsed
## 13.690 4.178 42.118
r2 # ddply
## user system elapsed
## 18.215 6.873 53.061
r3 # data.table
## user system elapsed
## 0.171 0.036 0.442
data.table in comparison to by and ddply, but maybe it shouldn't be surprise that the elegance of ddply comes with a price as well. Addition (13 June 2012): See also Matt's comments below. I completely missed
ave from base R, which is rather simple and quick as well. Additionally his link to a stackoverflow discussion provides further examples and benchmarks.Finally my session info:
> sessionInfo() # iBook G4 800 MHZ, 640 MB RAM
R version 2.15.0 Patched (2012-06-03 r59505)
Platform: powerpc-apple-darwin8.11.0 (32-bit)
locale:
[1] C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] latticeExtra_0.6-19 lattice_0.20-6 RColorBrewer_1.0-5
[4] data.table_1.8.0 plyr_1.7.1
loaded via a namespace (and not attached):
[1] grid_2.15.0
UK house prices visualised with googleVis-0.2.16
A new version of googleVis has been released on CRAN and the project site. Version 0.2.16 adds the functionality to plot quarterly and monthly data as a motion chart.
To illustrate the new feature I looked for a quarterly data set and stumbled across the quarterly UK house price data published by Nationwide, a building society. The data is available in a spread sheet format and presents the average house prices and indexed to 100 in Q1 1993 by region in the UK from Q4 1973 to Q1 2012. Unfortunately the data is formated for human eyes rather than for computers, see the screen shot below.
 |
| Screen shot of Nationwide's UK house price data in Excel |
install.packages("XLConnect", type="source")).Interactive HTML presentation with R, googleVis, knitr, pandoc and slidy
Tonight I will give a talk at the Cambridge R user group about googleVis. Following my good experience with knitr and RStudio to create interactive reports, I thought that I should try to create the slides in the same way as well.
Christopher Gandrud's recent post reminded me of deck.js, a JavaScript library for interactive html slides, which I have used in the past, but as Christopher experienced, it is currently not that straightforward to use with R and knitr.
Thus, I decided to try slidy in combination with knitr and pandoc. And it worked nicely.
I used RStudio again to edit my Rmd-file and knitr to generate the Markdown md-file output. Following this I run pandoc on the command line to convert the md-file into a single slidy html-file:
pandoc -s -S -i -t slidy --mathjax Cambridge_R_googleVis_with_knitr_and_RStudio_May_2012.md -o Cambridge_R_googleVis_with_knitr_and_RStudio_May_2012.html

Addition (2 June 2012)
Oh boy, knitr and Markdown are hitting a nail. With slidify by Ramnath Vaidyanathan another project sprung up to ease the creation of web presentations.End User Computing and why R can help meeting Solvency II
John D. Cook gave a great talk about 'Why and how people use R'. The talk resonated with me and highlighted why R is such a great tool for end user computing. A topic which has become increasingly important in the European insurance industry.
John's main point on why people use R is that R gets the job done and I think he is spot on. Of course that's the trouble with R sometimes as well, or to quote Bo again:
"The best thing about R is that it was developed by statisticians.
"The worst thing about R is that it was developed by statisticians."
Bo Cowgill, Google
Interactive reports in R with knitr and RStudio
 |
| Screen shot of RStudio with a knitr file (*.Rmd) in the top left window. Notice also the integrated knitr button. |
Here is a simple example. The knitr source code is available on Github.
Waterfall charts in style of The Economist with R
Waterfall charts are sometimes quite helpful to illustrate the various moving parts in financial data, in particular when I have positive and negative values like a profit and loss statement (P&L). However, they can be a bit of a pain to produce in Excel. Not so in R, thanks to the waterfall package by James Howard. In combination with the latticeExtra package it is nearly a one-liner to produce a good looking waterfall chart that mimics the look of The Economist:
 |
| Example of a waterfall chart in R |
library(latticeExtra)
library(waterfall)
data(rasiel) # Example data of the waterfall package
rasiel
# label value subtotal
# 1 Net Sales 150 EBIT
# 2 Expenses -170 EBIT
# 3 Interest 18 Net Income
# 4 Gains 10 Net Income
# 5 Taxes -2 Net Income
asTheEconomist(
waterfallchart(value ~ label, data=rasiel,
groups=subtotal, main="P&L")
)ggplot2, the Learning R blog has a post on this topic.
Next Kölner R User Meeting: 6 July 2012
The next Cologne R user group meeting is scheduled for 6 July 2012. All details are available on the new KölnRUG Meetup site. Please sign up if you would like to come along, and notice that there is also pub poll for the after "work" drinks. Notes from the first Cologne R user group meeting are available here.
From the Guardian's data blog: Visualising risk
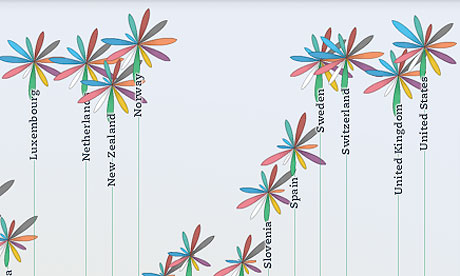 |
| OECD better life index |
Sweeping through data in R
How do you apply one particular row of your data to all other rows?
Today I came across a data set which showed the revenue split by product and location. The data was formated to show only the split by product for each location and the overall split by location, similar to the example in the table below.
Revenue by product and continent
|
I wanted to understand the revenue split by product and location. Hence, I have to multiply the total split by continent for each product in each column. Or in other words I would like to use the total line and sweep it through my data. Of course there is a function in base R for that. It is called sweep. To my surprise I can't remember that I ever used sweep before. The help page for sweep states that it used to be based on apply, so maybe that's how I would have approached those tasks in the past.
Anyhow, the sweep function requires an array or matrix as an input and not a data frame. Thus let's store the above table in a matrix.
Product <- c("A", "B", "C", "Total")
Continent <- c("Africa", "America", "Asia", "Australia", "Europe")
values <- c(0.4, 0.2, 0.4, 0.1, 0.3, 0.4, 0.3, 0.4, 0.5, 0.2,
0.3, 0.2, 0.4, 0.3, 0.3, 0.1, 0.4, 0.4, 0.2, 0.2)
M <- matrix(values, ncol=5, dimnames=list(Product, Continent))Now I can sweep through my data. The arguments for sweep are the data set itself (in my case the first three rows of my matrix), the margin dimension (here 2, as I want to apply the calculations to the second dimension / columns), the summary statistics to be applied (in my case the totals in row 4) and the function to be applied (in my scenario a simple multiplication "*"):
swept.M <- sweep(M[1:3,], 2, M[4,], "*")
The output is what I desired and can be plotted nicely as a bar plot.
> swept.M
Continent
Product Africa America Asia Australia Europe
A 0.04 0.12 0.10 0.04 0.08
B 0.02 0.16 0.04 0.03 0.08
C 0.04 0.12 0.06 0.03 0.04
barplot(swept.M*100, legend=dimnames(swept.M)[["Product"]],
main="Revenue by product and continent",
ylab="Revenue split %")

One more example
Another classical example for using thesweep function is of course the case when you have revenue information and would like to calculate the income split by product for each location:Revenue <- matrix(1:15, ncol=5)
sweep(Revenue, 2, colSums(Revenue), "/")This is actually the same as prop.table(Revenue, 2), which is short for:
sweep(x, margin, margin.table(x, margin), "/") Reading the help file for margin.table shows that this function is the same as apply(x, margin, sum) and colSum is just a faster version of the same statement.
Review: Kölner R Meeting 30 March 2012
The first Kölner R user meeting was great fun. About 20 useRs had turned up to exchange their ideas, questions and experience with R. Three talks about R & Excel, ggplot2 & XeLaTeX and Dynamical systems with R & simecol had kicked off the evening, with Kölsch (beer) losing our tongues further.
Thankfully a lot of people had brought along their laptops, as unfortunately we lacked a cable to connect any of the computers to the installed projector. Never-mind, we cuddled up around the notebooks and switched slides on the speakers sign.
 |
| Photos: Günter Faes |
Similar to LondonR, it was a very informal event. Maybe slightly forced by myself, as I called everyone by his/her first name, which could be considered rude in Germany. But what I had noticed in London, and the same was true also in Cologne, was that people with a very diverse background and of all ages would meet to discuss matters around R, often not working in the same field. So why worry about hierarchies?
Most attendees were not R experts, but users in its pure sense, trying to solve real life problems, and I suppose that makes those meetings so special. R users are often not programmers by trade, but amateurs, who have a keen interest to extract stories and pictures from their data. And for that reason the discussions are often so engaging. Talking to people using R in social science, psychology, biology, pharma, energy, telcos, finance, insurance or actually statistics opens your mind and eyes. You realise that you are not alone, other people are weird as well. They have similar problems and challenges, but may use a different domain language and look at problems from a different angle. And this can be incredibly refreshing!
Anyhow, we agreed to meet again in about three months time. The pub was a great venue to socialise, yet a bit noisy for the talks. Hopefully we can use a room at the nearby university for the presentations next time. Promises were made already. We shall see. Günter was so kind to set up a mailing list to which you can sign up here. I will continue to use this blog to provide updates on the Cologne R user group in the future and set up a public calendar as well.
Talks
Many thanks to the speakers, who dared to give the first talks and had to improvise on the spot without a projector. Please drop me a line if you would like to speak at one of the next events.
Reminder: Kölner R User Group meets on 30 March 2012

Venue: Sion em Keldenich, Weyertal 47, 50937 Cologne, Germany, 6 p.m., 30 March 2012,
For more details and registration see the Kölner R User Group page.
Copy and paste small data sets into R
How can I embed a small data set into my R code? That was the question I came across today, when I prepared my talk about Dynamical Systems in R with simecol for the forthcoming Cologne R user group meeting.
I wanted to add all the R code of the talk to the last slide. That's easy, but the presentation makes use of a small data set of 3 columns and 21 rows. Surely there must be an elegant solution that I can embed the data into the R code, without writing x <- c(x1, x2,...).
Of course there is a solution, but let's look at the data first. It shows the numbers of trapped lynx and snowshoe hares recorded by the Hudson Bay company in North Canada from 1900 to 1920.
 |
Data sourced from Joseph M. Mahaffy. Original data believed to be published in E. P. Odum (1953), Fundamentals of Ecology, Philadelphia, W. B. Saunders. Another source with data from 1845 to 1935 can be found on D. Hundley's page. |
Logistic map: Feigenbaum diagram in R
The other day I found some old basic code I had written about 15 years ago on a Mac Classic II to plot the Feigenbaum diagram for the logistic map. I remember, it took the little computer the whole night to produce the bifurcation chart.

logistic.map <- function(r, x, N, M){
## r: bifurcation parameter
## x: initial value
## N: number of iteration
## M: number of iteration points to be returned
z <- 1:N
z[1] <- x
for(i in c(1:(N-1))){
z[i+1] <- r *z[i] * (1 - z[i])
}
## Return the last M iterations
z[c((N-M):N)]
}
## Set scanning range for bifurcation parameter r
my.r <- seq(2.5, 4, by=0.003)
system.time(Orbit <- sapply(my.r, logistic.map, x=0.1, N=1000, M=300))
## user system elapsed (on a 2.4GHz Core2Duo)
## 2.910 0.018 2.919
Orbit <- as.vector(Orbit)
r <- sort(rep(my.r, 301))
plot(Orbit ~ r, pch=".")
Let's not forget when Mitchell Feigenbaum started this work in 1975 he did this on his little calculator!
Update, 18 March 2012
The comment from Berend has helped to speedup the code by a factor of about four, thanks to byte compiling (using the same parameters as above), and Owe got me thinking about the alpha value of the plotting colour. Here is the updated result, with the R code below:

library(compiler) ## requires R >= 2.13.0
logistic.map <- cmpfun(logistic.map) # same function as above
my.r <- seq(2.5, 4, by=0.001)
N <- 2000; M <- 500; start.x <- 0.1
orbit <- sapply(my.r, logistic.map, x=start.x, N=N, M=M)
Orbit <- as.vector(orbit)
r <- sort(rep(my.r, (M+1)))
plot(Orbit ~ r, pch=".", col=rgb(0,0,0,0.05))








{kind=link}
{kind=link}
No comments :
Post a Comment